Q-Learning with epsilon-decay
In this article, we will implement Q-learning with epsilon-decay. We implemented Q-learning in the previous article and therefore won’t be going into any detail. Come back after reading this article if you haven’t already.
what is epsilon-greedy?
It is an algorithm in reinforcement learning that controls the agent’s exploration v/s eploitation tradeoff.
Why is this a tradeoff?
Because eploration helps the agent find the best possible actions, with a low episodic reward being the possibility. Eploitation on the other hand refers to taking actions that maximise the short-term reward. This becomes an issue when the agent has not explored its environment and takes actions based on its current knowledge when it is possible that a higher reward action might be unexplored.
This is why we use epsilon-greedy algorithm. However, as the agent learns its environment, there is no need to to explore anymore. This can be issue with static epsilon value. Therefore, epsilon-decay is implemented to make it dynamic.
Environment

S is the start state and G is the goal state. Invalid moves are as follows:
- moving left when on S
- moving right when on G
Currently, the episode ends on G, therefore the agent is not able to take any action on reaching G.
Implementation
The value of epsilon is changed only when the agent reaches the goal state. This is how it is implemented for this example. You can check out complete code on github.
...
if new_state == 6:
reward = 10
self.epsilon *= self.decay_rate
...
The decay_rate is set to 0.99 in all the examples. You can experiment will various
different values like 0.9 or 0.999 or something different altogether, maybe?
Performance
The reward system can lead to very different behaviour of our agent. Keeping this in mind, here are three different reward systems with their performance charts.
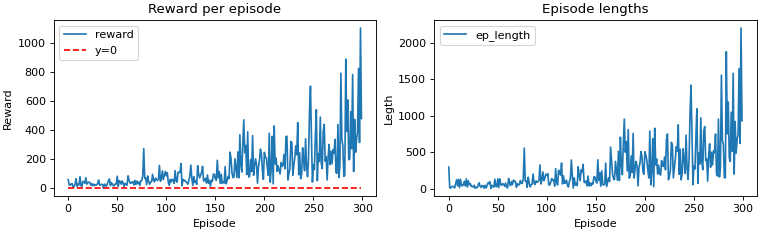
In our first reward system, the agent received +1 reward for moving towards the goal state,
-10 for invalid move and +10 for reaching the goal state. The episodes only end when
the agent reaches the goal state, which is evident from the chart below. Our agent took its
merry time to reach the goal state, receiving huge amount of reward in the process.
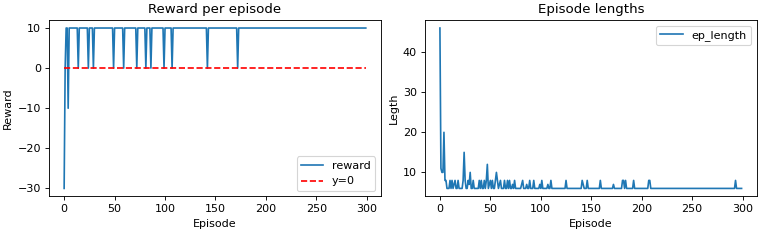
In our second reward system, the agent received -10 for invalid move and +10 for reaching
the goal state. However, this time there is no reward for any other move. Since there was no reward
other than for reaching goal state, the max reward is 10 in the chart below. Something else to note
is that the spikes in episode lengths decrease over time. The same is true with the next example too.
Finally, in our third reward system, the agent received -10 for invalid move and +10 for
reaching the goal state. Moreover, the agent is penalised for all other actions, i.e. -1 reward.
This reward system will penalise the agent for long episode lengths.
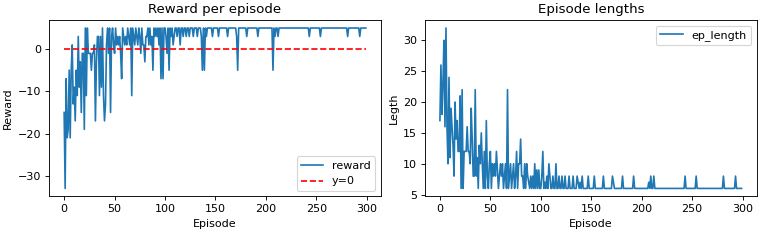
A final observation is that the episode length are comparatively small in second and third reward system. Only in the first example does the episode length grow over time.